Jak obliczyć, na ile mandatów może liczyć partia, jeśli znamy tylko ogólnopolskie wyniki sondaży? Są tu dwa podejścia, niczym przysłowiowe dwie szkoły – falenicka i otwocka. Pierwsza próbuje zrobić to tak, jak to się odbędzie, to znaczy obliczać podział mandatów dla każdego z okręgów z osobna. To jednak wymaga przyjęcia jakiegoś wzoru, opisującego jak np. ogólny wzrost poparcia o 1 pp. przekłada się na zmianę w każdym z okręgów. Można założyć, że poparcie wzrasta wszędzie o tyle samo, czyli 1 pp. – lecz może sensowniej byłoby przyjąć, że wzrosty są jakoś zróżnicowane i zależne od stanu wyjściowego. Takie szacunki można poczynić na podstawie wcześniejszych wyników wyborów. Tylko skąd mamy pewność, że kolejne zmiany będą mieć takie same charakterystyki, jak zmiany kilka lat wcześniej? Łatwo tu o błąd. Dlatego sam skłaniam się do drugiej szkoły, która opiera się na odkryciu, jak system D’Hondta przekształca głosy na mandaty (naukowy opis znaleźć można tu). Obrazowy opis tego mechanizmu jest oparty na metaforze kociołka i chochelki – partie przygotowują razem posiłek i każda z nich wrzuca do wspólnego kociołka pół mandatu za każdy okręg. Zawartość kociołka to zatem liczba partii razy 20,5. Potem każda z nich wyjada z kociołka mandaty chochelką wielkości swojego procentowego poparcia. Czyli w przypadku rywalizacji pięciu partii, ta z nich, która ma 40% poparcia dostanie jakieś 40 mandatów – po odliczeniu wcześniej poniesionych „kosztów” będzie mieć zatem „zysk” około 20 mandatów. Taka zaś, która ma 10% poparcia, wyje z kociołka tylko jakieś 10 mandatów, czyli będzie mieć 10 mandatów mniej, bo przecież wcześniej wrzuciła tam swój „wsad do kotła” w postaci 20,5 mandatu.
Takie przeliczenie jest proste – nie wymaga obliczania wyników dla każdego z okręgów z osobna. Prosta tabelka w Excelu pozwala od razu podzielić mandaty między partie. Tylko to zakłada, że wynik nie jest w żaden sposób skrzywiony. Tymczasem są dwa źródła możliwych skrzywień.
Po pierwsze siła głosu w poszczególnych okręgach nie jest równa. Zależy od liczby przydzielonych mandatów oraz różnic we frekwencji. Jeśli więc jakaś partia ma 30% poparcia, to może się okazać, że – jeśli ma większe poparcie w okręgach o niskiej frekwencji – że ono realnie odpowiada jednak np. 31%. Jeśli jednak jej poparcie jest w takich okręgach niższe od średniego, to jej realna siła może spaść do – powiedzmy – 29%.
Po drugie, ogólny wzór zakłada, że żadna partia nie miała szczególnego szczęścia ani wyjątkowego pecha i głosy zmarnowane w każdym z okręgów – naddatki na kolejny mandat, czyli właśnie ten „wsad” wrzucany do kociołka – odpowiadają średnio połowie mandatu. Można to sobie wyobrazić tak, że dla każdego z okręgów rzucamy kostką w grze o wielkość naszej straty. Jeśli rzucimy wyniki 1-3 to tracimy mandat, jeśli 4-6 nie. Powinniśmy stracić średnio 0,5 mandatu na okręg. Taka byłaby logika całego mechanizmu, gdybyśmy mieli nieskończenie wiele okręgów wyborczych. Lecz naszych okręgów jest 41. Nie działa tu jeszcze prawo wielkich liczb, lecz też szczególne odchylenia są bardzo mało prawdopodobne. Jakieś jednak mogą się zdarzyć.
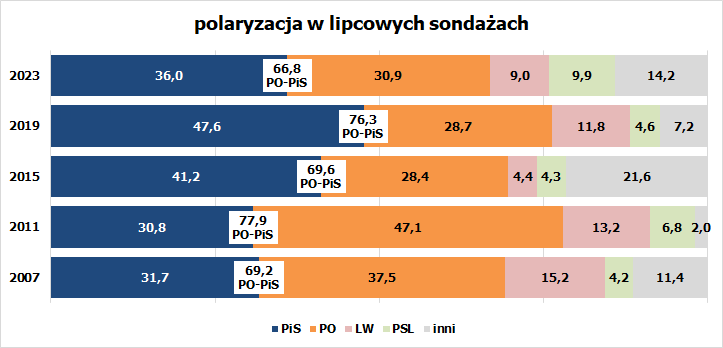
Mam świadomość, że takie odchylenia występują. Przekonują o tym dwa zestawienia. Pierwsze pokazuje, jakie różnice w liczbie zdobytych mandatów wynikały z uwzględnienia różnej siły głosu w okręgach. Policzyłem to tak, że głosy z każdego okręgu zważyłem ogólną siłą głosu, czyli liczbą głosów ważnych przypadającą na jeden mandat. Tak można ustalić efektywny procent poparcia. Taki procent przeliczyłem „chochelką” i odjąłem od wyników te ustalone na podstawie oficjalnych procentów poparcia. Wykres pokazuje takie nadwyżki i straty dla każdej partii czy kategorii partii osobno, lecz także bilans dla trójki partii tworzących dziś „Blok Senacki”. W czterech ostatnich wyborach wyglądało to tak:
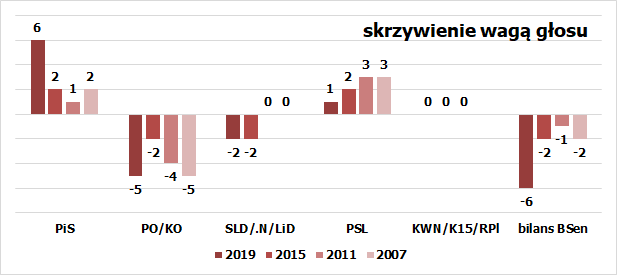
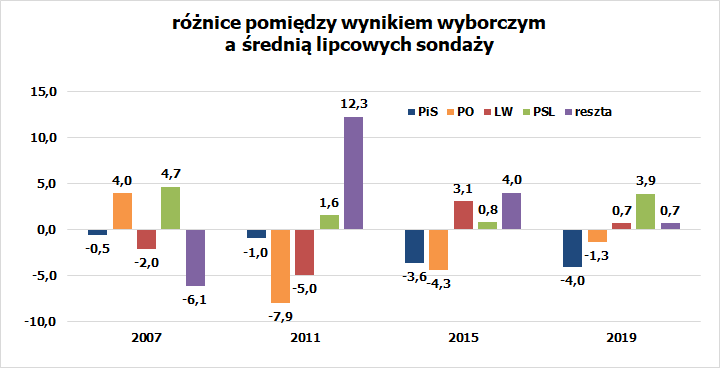
Widać, że są tu pewne wzory odchyleń, lecz przyjęcie na ich podstawie poprawki dla tegorocznych sondaży proste nie jest. Zanim do tego wrócę, jeszcze oszacowanie drugiego rodzaju odchyleń – takich, których nie da się wytłumaczyć systemowymi efektami. To różnica pomiędzy modelem z uwzględnieniem skrzywień wagą głosu a realnymi wynikami. Te wyglądały tak:
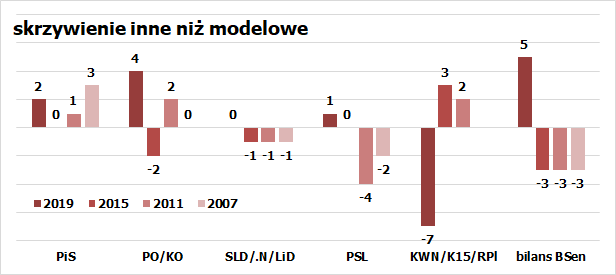
Tu już żywcem nie widać żadnych niepodważalnych wzorów. Każdej z dużych partii choć raz udało się idealnie wpasować w model. Bilans Bloku Senackiego wydawał się przez trzy kadencje stale ujemny, bo w ostatniej przeskoczyć zdecydowanie na drugą stronę. Poparcie dla Palikota i Kukiza układało się szczęśliwie, dając im dodatkowe mandaty, zaś zastępująca ich w roli czarnego konia Konfederacja była największym pechowcem.
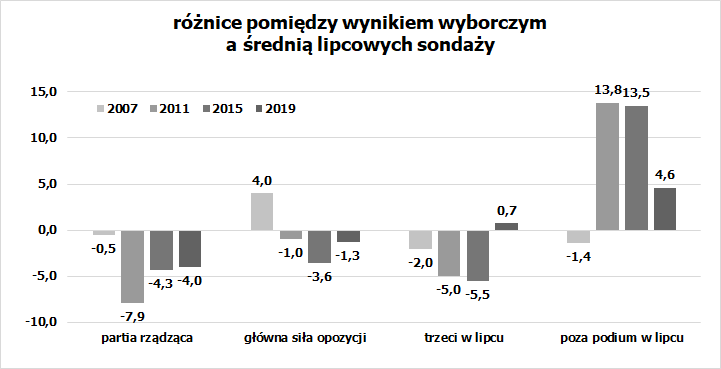
Te odchylenia można teraz dodać, pogrupować dla każdych wyborów oddzielnie i na koniec porównać z błędami sondaży – konkretnie zaś z różnicą pomiędzy realnymi wynikami a przeliczeniem „chochelką” średniej sondaży z ostatniego tygodnia (na podstawie zestawienia przygotowanego na potrzeby konkursu „Pytia”).
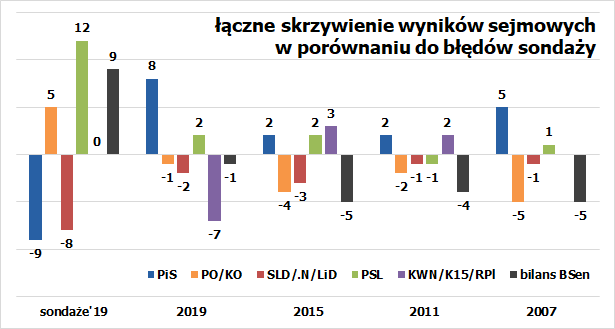
Gdyby ktoś miał na temat skrzywień wynikających z dystrybucji głosów każdej z partii pomiędzy okręgami genialną wiedzę i w ostatnim dniu kampanii, w oparciu o poprawkę z tego wynikającą, przeliczył średnią ostatnich sondaży, to jego prognoza niezwykle rozminęłaby się z rzeczywistością. PiS miałby w takiej prognozie 250 mandatów. Poprawka spotęgowałaby błędy sondaży.
Dodatkowo, model pozwalający przewidzieć odchylenia od standardowych spodziewanych wyników, trzeba nakarmić jakimiś danymi. Mogą to być sondaże (jak widać, o za małej precyzji) albo wyniki wcześniejszych wyborów. Testem trafności modeli stworzonych w oparciu o wcześniejsze dane, jest sprawdzenie, jaki jest błąd oszacowania dla dowolnego przypadku ze zbioru bazowego, jeśli stworzyć model w oparciu o wszystkie pozostałe przypadki. Tu mamy bazę w postaci czterech jedynie wyborów, więc można to sprawdzić dla każdej kombinacji. Czyli dla każdych wyborów z lat 2007-2019 liczymy średnie skrzywienie dla danej partii z pozostałej trójki głosowań i odejmujemy to rzeczywiste. Wychodzi to tak:
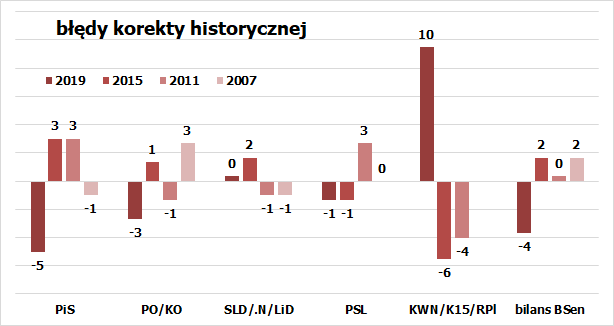
Odchylenia te nie są znacząco mniejsze niż precyzja samej „chochelki”, zastosowanej bez żadnej korekty. Tu akurat uwzględnienie historii choroby nie bardzo pomaga w przewidywaniu, co się nam przytrafi następnym razem. To właśnie dlatego wolę rozwiązanie prostsze, tylko powiązane z kluczowym zastrzeżeniem – to się może potoczyć trochę inaczej, ale nie mamy mocnych podstaw by sądzić, w którą stronę. Mamy po przeliczeniu generalne wyobrażenie, w którą stronę to idzie, lecz szczegóły, to i tak dopiero wyjdą w praniu, w noc powyborczą.
Moje podejście różni się jeszcze pod jednym względem od opinii niektórych zwolenników stosowania poprawek. Nie przychodzi mi do głowy twierdzić, że oni są niekompetentni i nieuchronnie tkwią w błędzie. Oni próbują po swojemu, ja po swojemu. Nie trzymam swojej wiedzy pod korcem – tabelkę w Excelu, pozwalającą w minutę przeliczyć wynik sondażu na mandaty, wysyłam wszystkim chętnym. Przypuszczam, że autorzy bardziej złożonych modeli nie będą chcieli wprowadzić postronnych w tajniki swojego podejścia. Choć może się mylę – w każdym razie chętnie bym się z tym podejściem zapoznał. Może mnie przekonają.
PS. Próbowałem kiedyś namówić kolegów-matematyków na stworzenie modelu rozrzucającego sondażowe poparcie po okręgach. Odpowiedzieli mi, że to się da zrobić tylko naruszając newralgiczne założenia o spodziewanych rozkładach poparcia i frekwencji. Choć zawsze można zastosować jakiś inny rozkład:
Obrazek z bardzo ciekawego opracowania Ireneusza Sadowskiego.